
La Líder de Ventas Técnicas de Concirrus, Mita Chavda, se presentó recientemente en el Congreso anual de ALSUM, discutiendo las habilidades de modelación de la compañía y la oportunidad que presentan para la industria de seguro marítimo.
Mita presentó recientemente este tema en el Congreso Anual de ALSUM. Para acceder a la grabación de la presentación en español por favor haga clic aquí (la presentación de Mita está en el minuto 2:40:00).
Nota original: https://www.concirrus.com/blog/making-waves-in-predictive-modelling
Hoy en día la tecnología está evolucionando a una tasa más rápida que nunca. En el sector del seguro marítimo algoritmos avanzados y modelaciones predictivas se han vuelto una parte importante en la evaluación de riesgos futuros. Mientras la adopción de tecnología innovativa se incrementa en el mercado, deberos asegurarnos de que los datos subyacentes que manejan estos algoritmos sean limpios y precisos para permitir que los resultados sean realmente predictivos de los futuros escenarios.
Otra forma de pensar en esto es imaginando que hay una receta para cocinar una torta. Usted puede seguir la receta y las instrucciones al pie de la letra, combinando los ingredientes correctos y horneando la torta a la temperatura correcta, y al final del proceso usted tendrá una torta como resultado. Sin embargo, si los ingredientes con los que comenzó son de baja calidad, por ejemplo, si los huevos estaban vencidos, entonces la torta no va a ser la mejor que haya probado. Lo mismo sucede cuando se utilizan algoritmos avanzados en el seguro marítimo: la calidad del resultado solo será tan buena como la calidad de la información suministrada.
Ahora discutiremos algunos de los algoritmos avanzados que Concirrus utiliza para ayudar a la comunidad del seguro marítimo a incrementar la precisión en la tarifación del riesgo, reducir pérdidas y desarrollar nuevos productos de seguro.
Seguro marítimo: algoritmos de optimización genética
Una de las formas en que se limpian los datos en el sector de casco marítimo es usando algoritmos de optimización genética para eliminar los datos falsos de la información de movimiento de los buques. Los datos de movimiento pueden mostrar una ruta estable de puntos de datos consecutivos múltiples de un buque navegando en una región. Sin embargo, en la mitad de la ruta estable podría haber algunos puntos aislados que podrían hacer creer que el buque está a moles de millas de distancia de la localización verdadera en pocos minutos (vea la figura 1). La línea de tiempos nos dice que esto es imposible, sin embargo los puntos de datos falsos son comunes en grupos de datos brutos.
 Figura 1: Ejemplo de un dato engañoso y su impacto en la ruta trazada
Figura 1: Ejemplo de un dato engañoso y su impacto en la ruta trazada
Esto puede ocurrir por muchas razones, pero generalmente se trata del hecho de que estamos utilizando datos reunidos por tecnología que fue diseñada para un propósito diferente. El Sistema de Identificación Automática (AIS) es un Sistema de rastreo de buques diseñado para alertar a las tripulaciones sobre otras embarcaciones en la zona y prevenir colisiones. Ahora estamos usando estos datos de localización a escala global para aprender sobre el comportamiento del buque y ello puede derivar en datos falsos o faltantes. El resultado significaría que cualquier factor de calificación de comportamiento derivado, como la velocidad y distancia recorrida por el buque, basado en estos datos brutos sería bastante sesgado y llevaría a predicciones inadecuadas. Con los algoritmos avanzados, se limpian 98% de los puntos engañosos, lo que significa que la alimentación de datos de los modelos predictivos se mantiene fiel al movimiento real del buque.
Seguro de Carga: Procesamiento de Lenguaje Natural (NLP)
Otro ejemplo es el uso del Procesamiento de Lenguaje Natural (NLP) para categorizar automáticamente mercancías. Esta puede ser una tarea difícil debido al uso tradicional de descripciones de texto libres, límites grandes de caracteres y miles de códigos armonizados. Una investigación de Concirrus ha resaltado que hasta un 80% de los portafolios de carga pueden ser categorizados bajo un código genérico tal como “carga general”. Esto resulta en una falta de evaluación de perfiles individuales de riesgo de bienes específicos, ocultando cargas de bajo y alto riesgo que deberían ser calificadas de forma distinta para ayudar a una mejor gestión del riesgo y mitigar pérdidas para el seguro de carga. Si no se toma una aproximación más enfocada, la industria corre el riesgo de que sus modelos predictivos den una misma calificación de riesgo para un contenedor lleno de peluches que uno con mercancías frágiles. Usando el NLP se puede proveer una visión detallada de los diferentes perfiles de riesgo dentro de un portafolio, leyendo de forma automática las descripciones de los bienes y categorizándolos correctamente.
 Figura 2: Ejemplo que muestra la recategorización de una carga utilizando el codificador de mercancías de Concirrus.
Figura 2: Ejemplo que muestra la recategorización de una carga utilizando el codificador de mercancías de Concirrus.
Modelos predictivos de frecuencia y severidad de nuevos siniestros
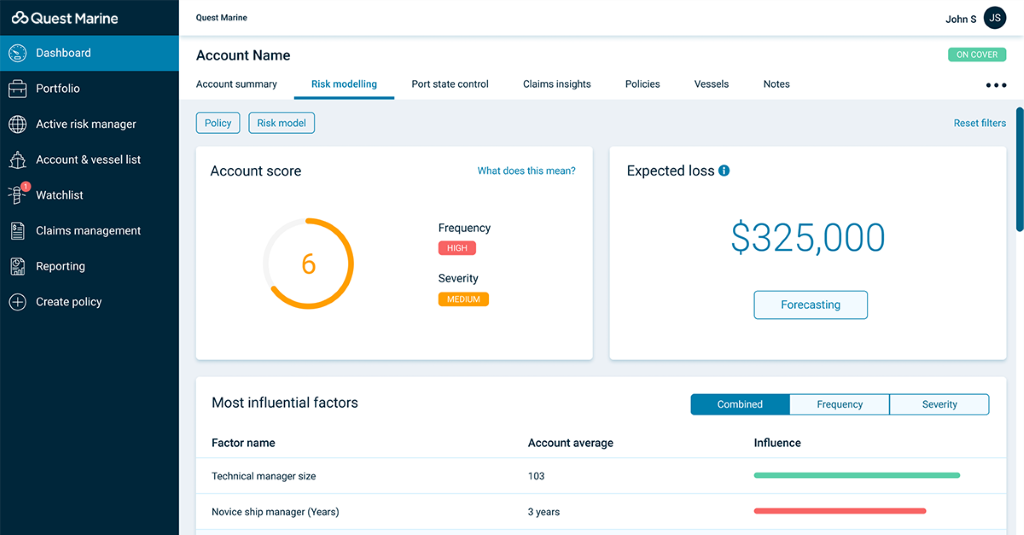
Quest reúne más de tres billones de datos brutos y los convierte en miles de factores de calificación para ser utilizados en tarifaciones más precisas y en gestión de riesgos.
La introducción de nuevos factores de calificación de comportamiento, tales como visitas a puerto o rutas tomadas por buques individuales, permite ver el riesgo marítimo en una nueva y sofisticada forma que profundiza nuestro entendimiento de cómo la exposición se correlaciona con la pérdida. Por ejemplo, cuando una señal AIS se recibe en Quest, la información sobre los datos, tiempo, latitud y longitud son incluidos en el paquete de datos. Una vez que temenos estos datos brutos, se puede determinar un número de factores de calificación relacionados con una embarcación individual, incluyendo:
- Distancia recorrida
- Tiempo tomado para navegar entre puntos de datos
- Velocidad del buque
- Cualquier señal perdida entre puntos de datos
- Visitas a puerto
- Duración de tiempo en puerto
- Visitas a zonas de alto riesgo o sancionadas
- Duración de tiempo en zonas de alto riesgo o sancionadas.
Quest combina nuevos factores de calificación de datos, bases de datos de terceros, y datos de exposición y siniestros de clientes antes de procesarlos a través de un marco de aprendizaje automático. Usando una variedad de algoritmos de aprendizaje automático independientes o apilados, tales como Aumento de gradiente, Árboles de decisión, Redes neuronales, etc., podemos identificar los algoritmos más fiables para usar en los modelos predictivos. Utilizando el coeficiente Gini y métricas de desviación para entender el poder predictivo de los diferentes algoritmos, podemos entonces seleccionar el más preciso y crear dos nuevos modelos que predicen:
- Frecuencia – el número de siniestros que probablemente ocurrirán en el siguiente año
- Severidad – el costo promedio de un siniestro
Desde ahí se pueden multiplicar los valores para no cubrir un valor de pérdida esperada y una puntuación de riesgo para un buque o una mercancía y ayudar con la evaluación y tarifación de riesgos existentes y nuevos de forma más precisa. Para mayor información sobre las capacidades de Concirrus sobre valores de pérdida esperados y puntuación de riesgos, haga clic aquí.
Esta metodología permite a la comunidad del seguro marítimo evaluar buques y cargas basados en datos de comportamiento en tiempo real, más que en factores estáticos. Como se vio en un reciente blog de Concirrus “Una visión de comportamiento de dos buques”, mientras que dos buques que pueden lucir idénticos basados en factores estáticos, sus comportamiento son un mejor indicador de riesgo y pueden ayudar al mercado a comprender mejor la selección y tarifación del riesgo.
En resumen
Con una cantidad de grandes datos creciendo como nunca antes y entrenando continuamente los modelos predictivos, es imperativo que estos datos sean completos, precisos, consistentes y válidos. Fallar en poner atención a los detalles en los datos subyacentes puede llevar a la industria por el camino equivocado, resultando en pérdidas no esperadas. Afortunadamente, la capacidad de modelos predictivos ha evolucionado y así también la tecnología para limpiar distintas fuentes de datos a gran escala.
Armados con estas tecnologías revolucionarias, la industria marítima puede trabajar hacia un futuro más seguro y rentable.
Descargue nuestro último libro blanco sobre tarifación predictiva aquí
[:en]Original blog: https://www.concirrus.com/blog/making-waves-in-predictive-modelling
Our Head of Technical Sales, Mita Chavda, recently presented at the ALSUM annual conference, discussing our modelling capabilities and the opportunity it presents for the marine insurance industry! Read on to learn more.
Mita recently presented this topic at the ALSUM annual conference. To access a recording of the presentation in Spanish please click here (Mita’s presentation is at 2 hours 40 minutes).
Today, technology is evolving at a faster rate than ever before. In the maritime insurance space, advanced algorithms and predictive modelling have become an important part of the assessment of future risk. As the adoption of innovative technology increases in the market, we must ensure that the underlying data driving these algorithms is clean and accurate to ensure that the results are truly predictive of future outcomes.
Another way to think about this idea is to imagine having a recipe to bake a cake. You could follow the recipe and instructions flawlessly, combining the correct ingredients and baking the cake at the right temperature, and at the end of process you would have a cake. However, if the ingredients you started with were of poor quality, for example, your eggs were past their use by date, then the cake is not going to be the best cake you’ve ever tasted! The same sentiment is true when using advanced algorithms in maritime insurance, the quality of the output will only be as good as the quality of the input.
Below we discuss a few of the advanced algorithms Concirrus use to help the maritime insurance community increase risk pricing accuracy, reduce losses and develop new insurance products.
Maritime insurance: Genetic optimisation algorithms
One of the ways we cleanse data in the marine hull space is by using genetic optimisation algorithms to rid vessel movement data of rogue data points. Movement data may show a steady route of multiple consecutive data points from a vessel sailing in one region. However, in the middle of the steady route there might be a few isolated data points that makes it appear as if the vessel is thousands of miles away from the true location within a matter of minutes (see figure 1). The timeline tells us that this is impossible, however rogue data points within raw location datasets are quite common.
Figure 1: Example of vessel spoofing and its impact on route data
This can occur for a multitude of reasons, but generally comes down to the fact that we are using data gathered from technology that was designed for a different purpose. Automatic Identification System (AIS) is a vessel tracking system designed to alert crews of other vessels in the immediate area to prevent collisions. We’re now using this location data at a global scale to learn more about
vessel behaviour and this can result in rogue and/or missing data. The result would mean that any derived behavioural rating factors such as vessel speed and distance travelled based on this raw data would be heavily skewed and would lead to inaccurate predictions. With our advanced algorithms, we cleanse 98% of spoofed points, meaning that the data feeding our predictive models remains true to actual vessel movements.
Cargo insurance: Natural Language Processing (NLP)
Another example is our use of Natural Language Processing (NLP) to automatically categorise cargo commodities. This can be a difficult task owing to the traditional use of free text descriptions, large character limits and thousands of harmonised codes.
Our research has highlighted that as much as 80% of cargo portfolios could be categorising goods under a generic code such as “general cargo”. This results in individual risk profiles associated with specific goods being disregarded, masking pockets of low and high risk cargo that should be rated differently to help better manage risk and mitigate losses within cargo insurance. Without taking a more focused approach, the industry runs the risk of its predictive models providing the same risk rating for a container filled with cuddly toys and a container filled with fragile goods. Using NLP we can provide detailed insight into the different risk profiles within a portfolio by automatically reading commodity descriptions and categorising them correctly.
Figure 2: Example showing the recategorizing of cargo using the Concirrus commodity coder
New claims frequency and severity predictive models
Quest ingests more than three trillion raw data points and converts them into thousands of rating factors for use in more accurately pricing and managing risk.
The introduction of new behavioural rating factors such as port visits, or routes taken by individual vessels allow us to view maritime risk in a new, sophisticated way that deepens our understanding of how exposure correlates to loss. For example, when an AIS signal is received within Quest, information regarding the data, time, latitude and longitude is included within the data package. Once we have this raw data a number of rating factors relating to an individual vessel can be determined, including:
- Distance travelled
- Time taken to travel between data points
- Speed of vessel
- Any signal loss between data points
- Port visits
- Length of time in port
- Visits to high risk/sanctioned zones
- Length of time in high risk/sanctioned zones
Quest combines new rating factor data, third party datasets, client exposure and claims data before running it through our machine learning framework. Using a variety of independent or stacked machine learning algorithms such as Gradient Boosting, Decision Trees, Neural Networks etc… we can identify the most reliable algorithms for use in our predictive models. Using the gini coefficient and deviance metrics to understand the predictive power of the different algorithms we can then select the most accurate and create two new models that predict:
- Frequency – the number of claims likely to occur in the following year
- Severity – the average cost of a claim
From here we can multiply the values to uncover an expected loss value and a risk score for a vessel or piece of cargo to aid with the assessment and pricing of new and existing risks more accurately. For more information on our expected loss values and risk scoring capabilities click here.
This methodology enables the maritime insurance community to evaluate vessels and cargo based on real-time behavioural data rather than static factors alone. As we saw in our recent blog: ‘A behavioural view of two ships’, whilst two vessels can look identical based on static factors, behaviour is a better indicator of risk and can help the market better understand risk selection and pricing.
In summary
With an ever-increasing amount of big data continuously training our predictive models, it is imperative that this data is complete, accurate, consistent, and valid. Failure to pay attention to the detail in the underlying data could set the industry on the wrong path resulting in unforeseen losses. Fortunately, as our predictive modelling capability has evolved, so has the technology to cleanse different data sources on a large scale. Armed with these types of revolutionary technologies, the maritime industry can work towards a safer and more profitable future.
Download our latest predictive pricing white paper below.
[:pb]A Líder de Vendas Técnicas da Concirrus, Mita Chavda, apresentou-se recentemente no Congresso Anual da ALSUM, onde discutiu as habilidades de modelagem da empresa e a oportunidade apresentada para a indústria de seguros marítimos.
Recentemente Mita apresentou este tema no Congresso Anual ALSUM . Para acessar a gravação da apresentação em espanhol clique aqui (A apresentação da Mita está no minuto 14h40).
Nota original: https://www.concirrus.com/blog/making-waves-in-predictive-modelling
Hoje, a tecnologia está evoluindo a um ritmo mais rápido do que nunca. Na indústria de seguros marítimos, algoritmos avançados e modelagem preditiva se tornaram uma parte importante da avaliação de riscos futuros. Conforme a adoção de tecnologias inovadoras aumenta no mercado, devemos garantir que os dados subjacentes que esses algoritmos manipulam, sejam limpos e precisos para permitir que os resultados sejam realmente preditivos de cenários futuros.
Outra maneira de pensar sobre isso é imaginar uma receita para fazer um bolo. Você pode seguir a receita e as instruções ao pé da letra, combinando os ingredientes corretos e assando o bolo na temperatura correta, e ao final do processo terá como resultado um bolo. No entanto, se os ingredientes com os quais você começou são de baixa qualidade, por exemplo, se os ovos estavam estragados, então o bolo não será o melhor que você já comeu. O mesmo acontece quando algoritmos avançados são usados no seguro marítimo: a qualidade do resultado será tão boa quanto a qualidade da informação fornecida.
Agora discutiremos alguns dos algoritmos avançados que a Concirrus usa para ajudar a comunidade de seguros marítimos a aumentar a precisão da precificação de risco, reduzir perdas e desenvolver novos produtos de seguro.
Seguro marítimo: algoritmos de otimização genética
Uma das maneiras pelas quais os dados são limpos no setor do casco marítimo é usando algoritmos de otimização genética para remover dados falsos das informações de movimento do navio. Os dados de movimento podem mostrar uma rota estável de vários pontos de dados consecutivos de uma embarcação navegando em uma região. No entanto, no meio da rota estável podem haver alguns pontos isolados que podem levar a crer que o navio está a alguns minutos de distância do seu verdadeiro local (ver figura 1). A linha do tempo nos diz que isso é impossível, no entanto, pontos de dados falsos são comuns em conjuntos de dados brutos.
Figura 1: Exemplo de dados enganosos e seu impacto na rota desenhada
Isso pode ocorrer por vários motivos, mas geralmente é o fato de que estamos usando dados coletados por tecnologia projetada para uma finalidade diferente. O Sistema de Identificação Automática (AIS) é um Sistema de Rastreamento de Embarcações projetado para alertar as tripulações sobre outras embarcações na área e evitar colisões. Agora estamos usando esses dados de localização em escala global para aprender sobre o comportamento do navio e isso pode levar a dados falsos ou ausentes. O resultado significaria que quaisquer fatores derivados de classificação de desempenho, como velocidade e distância percorrida pela embarcação, com base nesses dados brutos, seriam bastante tendenciosos e levariam a previsões inadequadas. Com algoritmos avançados, 98% dos pontos enganosos são limpos, o que significa que a alimentação de dados dos modelos preditivos permanece fiel ao movimento real da embarcação.
Seguro de carga: Processamento de Linguagem Natural (PNL)
Outro exemplo é o uso de Processamento de Linguagem Natural (PNL) para categorizar mercadorias automaticamente. Isso pode ser uma tarefa difícil devido ao uso tradicional de descrições de texto livre, grandes limites de caracteres e milhares de códigos harmonizados. Uma pesquisa da Concirrus destacou que até 80% das carteiras de carga podem ser categorizadas sob um código genérico, como “carga geral”. Isso resulta em uma falta de avaliação dos perfis de risco específicos de ativos individuais, ocultando encargos de baixo e alto risco que deveriam ser classificados de forma diferente para ajudar a gerenciar melhor o risco e mitigar perdas para seguro de carga. Se uma abordagem mais focada não for adotada, a indústria corre o risco de que seus modelos preditivos forneçam a mesma classificação de risco para um contêiner cheio de bichos de pelúcia e um com produtos frágeis. Usando a PNL, uma visão detalhada dos diferentes perfis de risco dentro de um portfólio pode ser fornecida, lendo automaticamente as descrições dos ativos e categorizando-as corretamente.
Figura 2: Exemplo que mostra a recategorização de uma carga usando o codificador de mercadoria Concirrus.
Modelos preditivos para a frequência e gravidade de novos sinistros
A Quest reúne mais de três trilhões de dados brutos e os converte em milhares de fatores de classificação para serem usados em preços mais precisos e gerenciamento de riscos.
A introdução de novos fatores de classificação comportamental, como visitas a portos ou rotas feitas por embarcações individuais, nos permite ver o risco marítimo de uma forma nova e sofisticada que aprofunda nosso entendimento de como a exposição se correlaciona com a perda. Por exemplo, quando um sinal AIS é recebido na Quest, informações sobre os dados, hora, latitude e longitude são incluídas no pacote de dados. Assim que tivermos esses dados brutos, uma série de fatores de classificação relacionados a uma embarcação individual podem ser determinados, incluindo:
- Distância percorrida.
- Tempo gasto para navegar entre os pontos de dados.
- Velocidade do navio.
- Qualquer sinal perdido entre os pontos de dados.
- Visitas ao porto.
- Duração do tempo no porto.
- Visitas a áreas de alto risco ou sancionadas.
- Duração do tempo em áreas de alto risco ou sancionadas.
A Quest combina novos fatores de pontuação de dados, bancos de dados de terceiros e dados de exposição e sinistros de clientes antes de processá-los por meio de uma estrutura de aprendizado de máquina. Usando uma variedade de algoritmos de aprendizado de máquina autônomos ou empilhados, como o Aumento de Gradiente, Árvores de Decisão, Redes Neurais, etc., podemos identificar os algoritmos mais confiáveis para usar em modelos preditivos. Usando o coeficiente de Gini e as métricas de desvio para entender o poder preditivo dos diferentes algoritmos, podemos então selecionar o mais preciso e criar dois novos modelos de previsão:
- Frequência – o número de sinistros que provavelmente ocorreriam no ano seguinte
- Gravidade – o custo médio de um sinistros
A partir daí, os valores podem ser multiplicados para não cobrir um valor de perda esperado e uma pontuação de risco para um navio ou mercadoria e ajudar com a avaliação e precificação de riscos existentes e novos com mais precisão. Para obter mais informações sobre os recursos do Concirrus sobre valores de perda esperada e pontuação de risco, clique aqui.
Essa metodologia permite que a comunidade de seguros marítimos avalie navios e cargas com base em dados comportamentais em tempo real, em vez de fatores estáticos. Como visto em um recente blog da Concirrus “Uma visão do comportamento de duas embarcações”, enquanto duas embarcações que podem parecer idênticas com base em fatores estáticos, seu comportamento é um melhor indicador de risco e pode ajudar o mercado a entender melhor a seleção e precificação de risco.
Resumo
Com uma quantidade de big data crescendo como nunca antes e treinamento continuo de modelos preditivos, é fundamental que esses dados sejam completos, precisos, consistentes e válidos. Deixar de prestar atenção aos detalhes nos dados subjacentes pode levar a indústria para o caminho errado, resultando em perdas inesperadas. Felizmente, os recursos de modelagem preditiva evoluíram, assim como a tecnologia para limpar várias fontes de dados em grande escala.
Armado com essas tecnologias revolucionárias, a indústria marítima pode trabalhar para um futuro mais seguro e lucrativo.
Baixe nosso último livro branco sobre tarifação preditiva aqui
[:].